Writing
Blog posts, perspective pieces, and research explainers.
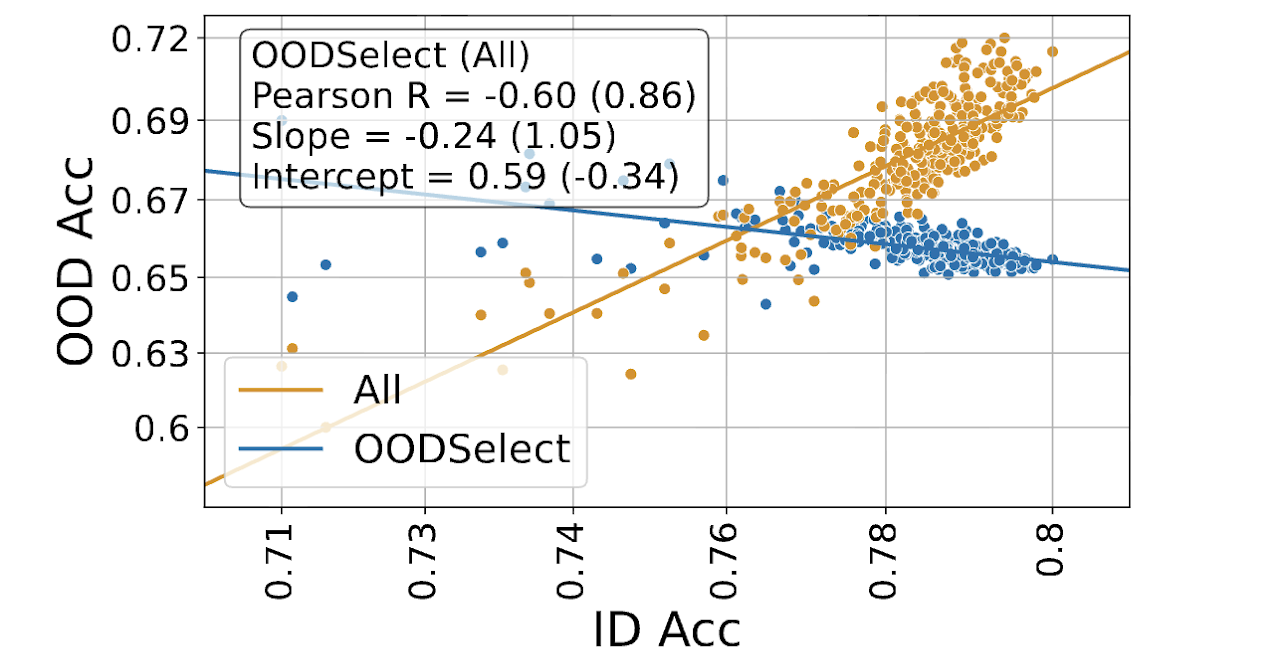
Aggregation Hides Out-of-Distribution Generalization Failures from Spurious Correlations
measurement
generalization
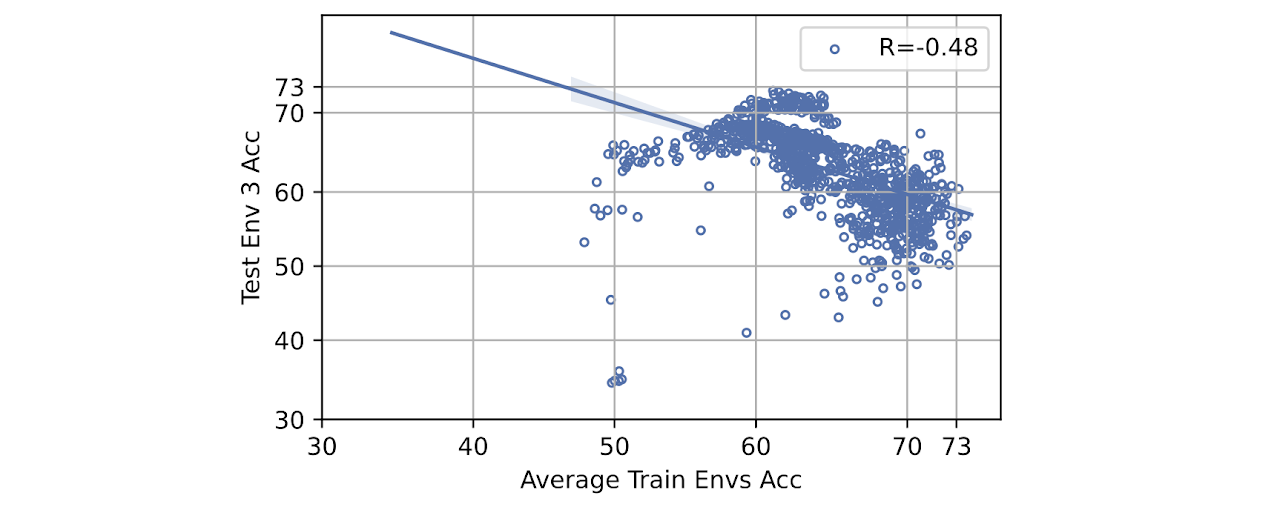
Are Domain Generalization Benchmarks with Accuracy on the Line Misspecified?
measurement
generalization
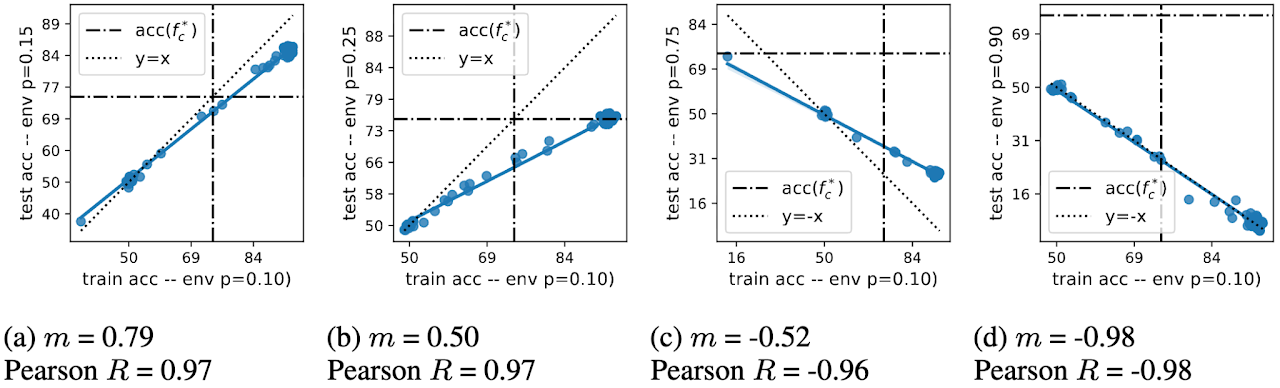
On Domain Generalization Datasets as Proxy Benchmarks for Causal Representation Learning
measurement
generalization
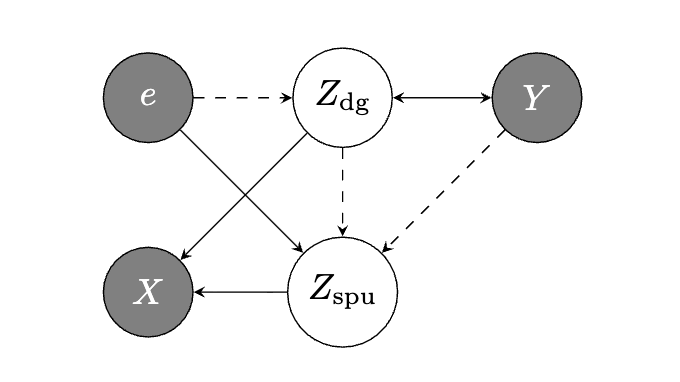
Causally Inspired Regularization Enables Domain General Representations
intervention
generalization
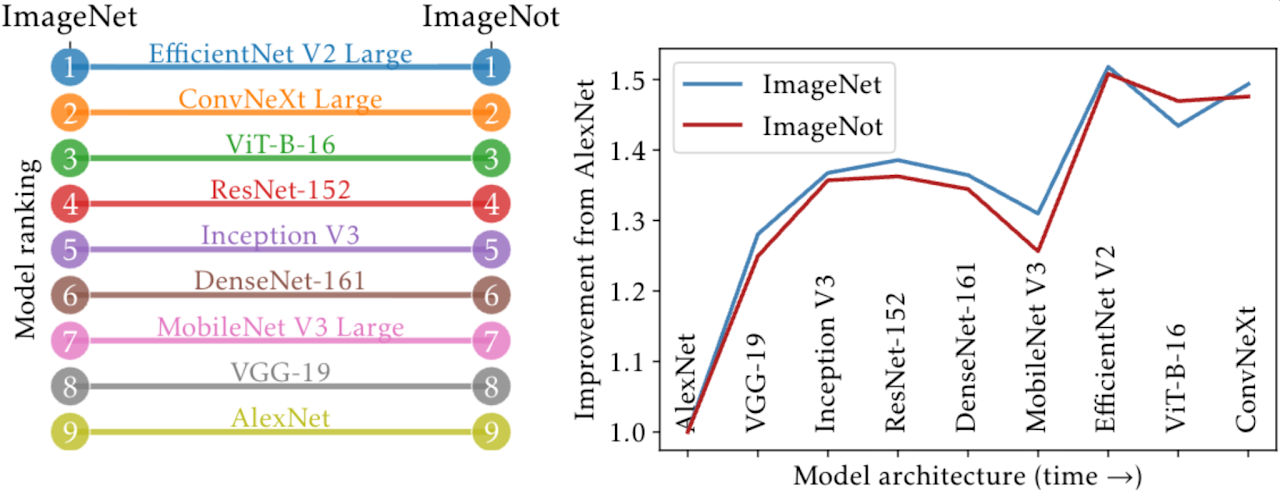
ImageNot: A contrast with ImageNet preserves model rankings
measurement
generalization
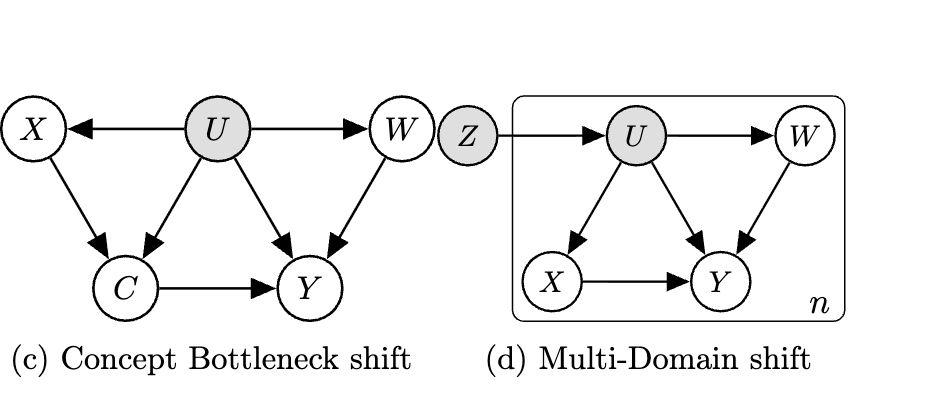
Adapting to Latent Subgroup Shifts via Concepts and Proxies
intervention
generalization
No matching items